Supervised vs Unsupervised Learning
Classifying statistical learning problems as:
- Supervised
- Unsupervised
Supervised Learning
For this domain, each observation or input has an associated response. The goal is to fit a model that relates the response to the predictors, with the hopes of accurately predicting the response (Prediction) or understanding the relationship between the predictor and the response (Inference).
- Examples include:
- Linear regression, Logistic regression
- Generalized Additive Models, Boosting, Support Vector Machines
Unsupervised Learning
Here, we observe a vector of measurements, but there is no associated response. In a way, there is no north star; in a way, we are working blind. We lack a response variable that supervises our model. We are only concerned about understanding the relationships between the given variables or observations.
- Examples include:
- Cluster analysis, where we find structure or patterns among observations
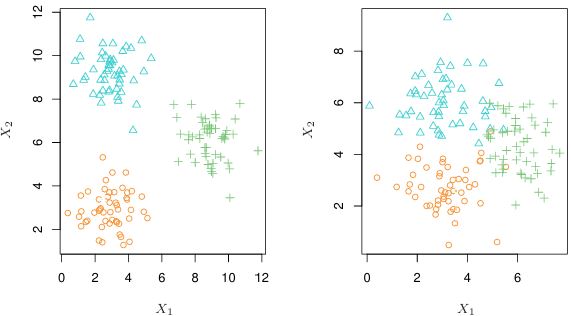
Above is an example of a clustering analysis using two variables. The left plot shows that groups are well separated, while the right plot shows some overlapping clusters, making perfect assignments impossible. High dimensional data with many variables can also make visual inspection impractical - thus automated clustering methods are essential.
Semi-supervised learning
Sometimes, only part of the data set has both predictors and responses, while the rest has predictors only. This happens when predictors are cheap to collect but responses are costly. The goal then is to use methods that leverage both labeled and unlabeled data.